



بياناتك الخاصة،
محللة بواسطة الذكاء الاصطناعي
نحن نبني حلول مخصصة تقنية الاسترجاع المعزز بالتوليد (RAG) أنظمة تربط مستنداتك وقواعد بياناتك وقواعد المعرفة الخاصة بك بنماذج اللغة الكبيرة — مما يمنحك الفريق / العملاء إجابات فورية ودقيقة بناءً على البيانات المضمنة.
• RAG AI
نظام ذكاء اصطناعي يعرف عملك، وليس فقط الإنترنت
نماذج الذكاء الاصطناعي القياسية مثل GPT-4 مدربة على بيانات الإنترنت العامة — فهي لا تعرف سياساتك الداخلية، مواصفات المنتجات، تاريخ العملاء، أو الأبحاث الملكية الخاصة بك. نظام RAG ((RAG)) يسد هذه الفجوة.

بدلاً من الاعتماد على بيانات المدخلة يدويًا، يقوم نظام RAG باسترجاع الأجزاء الأكثر صلة من قاعدة بياناتك الخاصة بأسرع وقت ممكن ثم يزودها إلى نموذج الذكاء الاصطناعي كنص — مما ينتج إجابات دقيقة ومحدثة وقابلة للتتبع بالكامل إلى مصادرها الخاصة.
85%
تقليل الهلوسة في ردود الذكاء الاصطناعي
10x
الحصول على المعلومات بشكل أسرع
100%
البيانات تبقى ضمن البنية التحتية

ثلاث خطوات من السؤال إلى افضل إجابة موثوقة
تم تصميم هندسة RAG لدينا للسرعة والدقة والقابلية الكاملة للتدقيق — كل إجابة قابلة للتتبع إلى مصدرها.
مهما كان مصادر بياناتك، سيتم تحويلها إلى بيانات قابلة للبحث
نقوم بالاتصال بمصادر بياناتك — ملفات PDF، مستندات Word، قواعد البيانات، SharePoint، Confluence، S3، واجهات برمجة التطبيقات — نقسم المحتوى وندمجه باستخدام نماذج Embedding المتقدمة، ثم نخزنه في قاعدة بيانات عالية الأداء (Pinecone، Qdrant، Weaviate، أو pgvector).
- يدعم أكثر من 50 نوع ملف
- إعادة الفهرسة والترتيب عند تغير البيانات
- استخراج البيانات المرتبطة بالسؤال فقط للتحكم في سرعة الرد والدقة
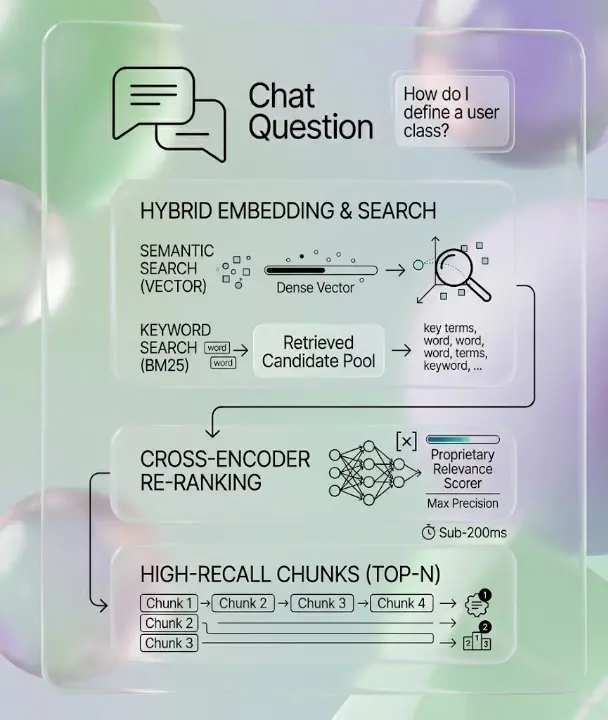
اعثر على المحتوى الدقيق من ملايين المستندات في غضون مللي ثانية
عندما يطرح المستخدم سؤالًا، يقوم طبقة الاسترجاع لدينا بتحويله إلى متجه تضمين ويجري بحث تشابه دلالي سريع للغاية — مما يعيد أكثر أجزاء المحتوى صلة، مع إعادة ترتيبها بواسطة مقيم الصلة الخاص بنا لتحقيق أقصى دقة.
- البحث الهجين (المتجه + الكلمة الرئيسية BM25) لاسترجاع أعلى
- إعادة الترتيب عبر الترميز المتقاطع للدقة
- استرجاع أقل من 200 مللي ثانية على مجموعات تحتوي على ملايين السجلات

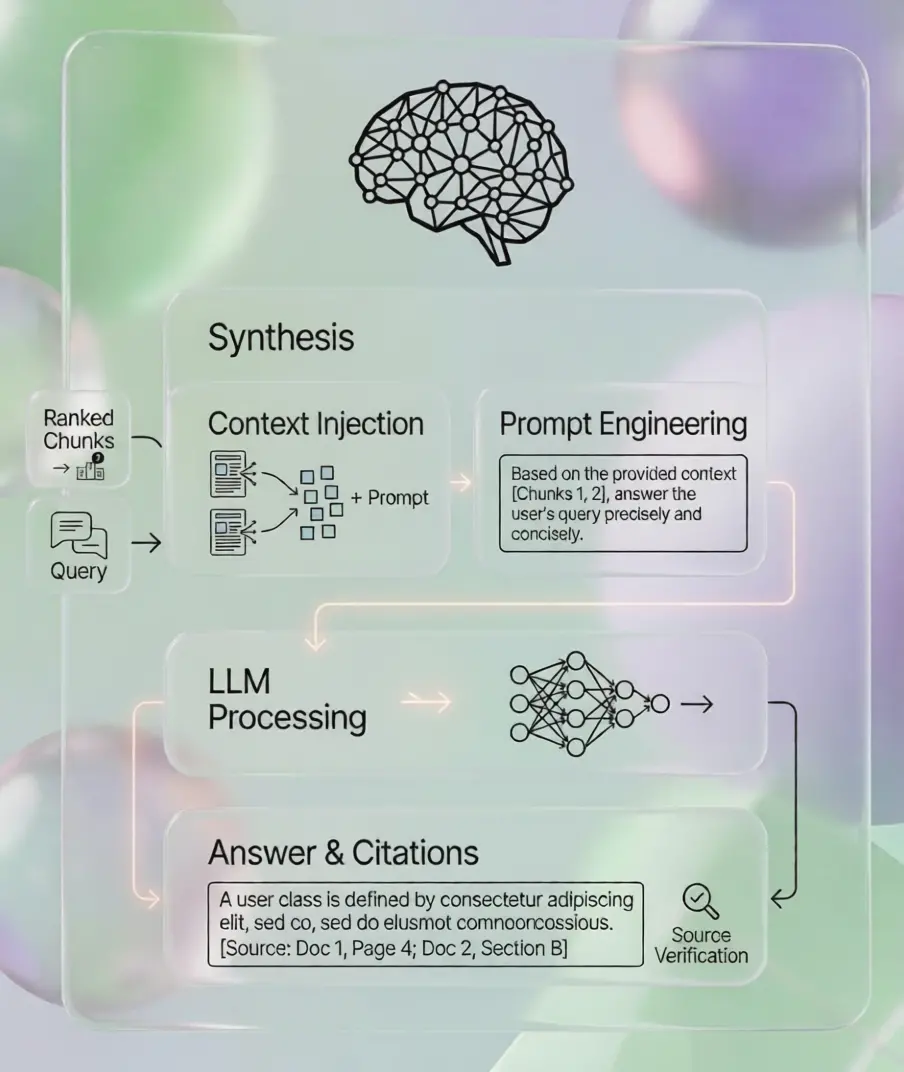
إجابات موثوقة ومستندة إلى المصادر يمكن لفريقك الوثوق بها
يتم حقن المحتوى المسترجع في موجه مصمم بعناية وإرساله إلى نموذج اللغة (LLM) الذي اخترته. يقوم النموذج بتوليد إجابة دقيقة وقابلة للقراءة البشرية — مصحوبة بالاستشهادات المصدرية حتى يتمكن المستخدمون من التحقق من كل ادعاء مقابل المستند الأصلي.
- استشهادات داخلية تلقائية مع مراجع الصفحة/القسم
- تقييم الثقة ورسائل الاسترجاع البديلة
- سجل تدقيق كامل للامتثال وقابلية التتبع
• RAG Pipeline
البيانات هي الملك، لذا نبني تطبيقات مكثفة البيانات
كل نظام RAG نبنيه مصمم من الصفر ليتناسب مع حالة الاستخدام الخاصة بك، وهيكل البيانات، ومتطلبات الأمان.
استيعاب البيانات من مصادر متعددة
الاتصال بملفات PDF، مستندات Word، جداول Excel، قواعد بيانات SQL، واجهات برمجة التطبيقات REST، SharePoint، Notion، Google Drive، والمزيد. نحن نبني موصلات مخصصة لأي مصدر بيانات يعتمد عليه فريقك.
البحث الهجين (المتجه + الكلمة الرئيسية)
يجمع بين البحث الدلالي المتجه الكثيف ومطابقة الكلمات الرئيسية النادرة BM25 للحصول على أفضل استرجاع من كلا العالمين. استرجاع أعلى، دقة أفضل، وعدد أقل من الإجابات المفقودة.
التحكم في الوصول بناءً على الدور
Enforce document-level permissions inside the RAG pipeline. Users only retrieve content they're authorized to see — fully synchronized with your existing IAM, SSO, or LDAP.
أي نموذج لغة كبير، اختيارك
نحن نتكامل مع OpenAI GPT-4o، Anthropic Claude، Google Gemini، Mistral، والنماذج مفتوحة المصدر المستضافة ذاتيًا (Llama 3، Phi-3، Qwen). لا قيود على البائع.
الذاكرة الحوارية
دعم المحادثات متعددة الأدوار مع إدارة ذاكرة الجلسة ونافذة المحتوى. يمكن للمستخدمين طرح أسئلة متابعة بشكل طبيعي — يتذكر النظام المحتوى.
التحليلات ودورة التغذية الراجعة
يتتبع لوحة التحكم المدمجة حجم الاستفسارات، دقة الاسترجاع، درجات رضا المستخدمين، والأسئلة غير المجابة — مما يتيح التحسين المستمر لقاعدة معرفتك.
• Industry
تحويل طريقة وصول الصناعات إلى المعرفة
أنظمة RAG ليست مقاسًا واحدًا يناسب الجميع. إليك كيف نخصصها لقطاعات مختلفة.
تقارير ذكية مع الرسوم البيانية
إنشاء تقارير مع رسوم بيانية وتصورات تفاعلية، مما يجعل تحليل البيانات بديهيًا وقابلًا للتنفيذ. مثالي للتحليل المالي، أبحاث السوق، وأي سيناريو يحتاج فيه إلى توصيل الرؤى بوضوح.
ناقش حالة استخدام تقاريرك
دعم الذكاء الاصطناعي على قاعدة معرفتك
استبدل روبوتات الدردشة العامة بوكيل ذكاء اصطناعي يقرأ مستندات المنتج الفعلية، والأسئلة الشائعة، وسجل التذاكر. حل 70٪ من استفسارات المستوى الأول على الفور، مع استجابات دقيقة ومتوافقة مع العلامة التجارية وتصعيد تلقائي للقضايا المعقدة.
بناء نظام RAG لدعمك
المستندات السريرية وأسئلة وأجوبة البحث
استفسر عن الإرشادات السريرية، والأدبيات الطبية، وسجلات المرضى (متوافقة مع HIPAA، على الموقع)، والأوراق البحثية. عرض الإجابات المستندة إلى الأدلة أسرع من أي عملية مراجعة يدوية.
استكشاف نظام RAG للرعاية الصحية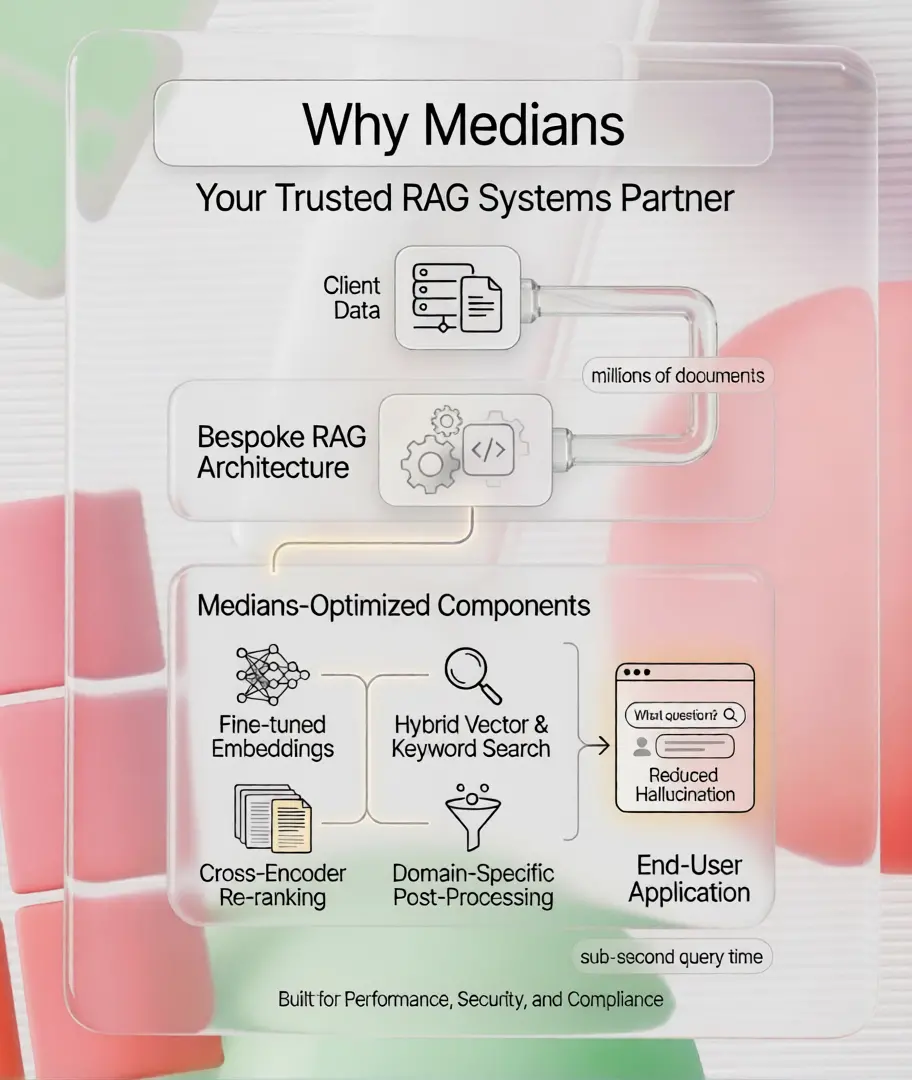
مساعد المعرفة للفرق
امنح كل موظف مساعد بحث داخلي رائع. يتم دمج الموظفين الجدد بسرعة ثلاثة أضعاف. يتوقف الموظفون الكبار عن التعامل مع الأسئلة المتكررة. تصبح سياسات الموارد البشرية، وكتب التشغيل، وإجراءات التشغيل القياسية، وملاحظات الاجتماعات قابلة للبحث على الفور.
بناء نظام RAG لفريقكنحن لا نقدم أفكارًا. نحن ننتج نتائج حقيقية.
تم البناء من مبادئ مكثفة البيانات
نحن لا نستخدم أغلفة الكود أو السكريبتات المسبقة. كل نظام مصمم خصيصًا لمخطط البيانات الخاص بك، ومصادر البيانات، ومتطلبات العمل.
الأمان أولاً حسب التصميم
خيارات النشر في الموقع، التشفير من النهاية إلى النهاية، التحكم في الوصول بناءً على الدور في طبقة الاسترجاع، والامتثال الكامل لمعايير OWASP. بياناتك لا تغادر بنيتك التحتية إلا إذا اخترت السحابة.
الاعتمادية وقابلية التوسع
لا يهم كمية أو عدد البيانات. تستخدم بنيتنا التحتية مخازن متجهات موزعة وقوائم إعادة الفهرسة غير المتزامنة للتعامل مع أي حجم دون تقليل جودة الاستجابة.
الدعم المستمر والمتواصل
نحن لا نختفي بعد الإطلاق. نحن نقدم واجهات برمجة تطبيقات موثقة، ولوحات إدارة، وتدريب الفريق، وقناة دعم مخصصة — حتى يتمكن فريقك من امتلاك النظام وتطويره.
50+
أنظمة RAG المنشورةعبر القطاعات القانونية، والرعاية الصحية، والتكنولوجيا المالية، والمؤسسات
<200ms
متوسط زمن استرجاع البياناتأقل من 200 مللي ثانية P95 على المجموعات التي تحتوي على أكثر من 10 ملايين متجه
98%
معدل دقة الإجابةتم القياس على معايير التقييم المحددة من قبل العميل
• Medians
التقنيات التي نعمل بها