



Your Private Data,
Analyzed by AI
We build custom Retrieval-Augmented Generation (RAG) systems that connect your documents, databases, and knowledge bases to large language models — giving your Team / Clients instant, accurate answers based on included data.
• RAG AI
AI System that knows your business, not just the internet
Standard AI models like GPT-4 are trained on public internet data — they don't know your internal policies, product specs, customer history, or proprietary research. RAG (Retrieval-Augmented Generation) bridges this gap.

Instead of relying on memorized training data, a RAG system retrieves the most relevant chunks from your private knowledge base in real time, then feeds them into the AI model as context — producing answers that are accurate, up-to-date, and fully traceable to your own sources.
85%
Reduction in AI hallucination
10x
Faster knowledge retrieval
100%
Data stays within infrastructure

Three steps from question to trusted answer
Our RAG architecture is engineered for speed, accuracy, and full auditability — every answer is traceable to a source.
Your knowledge base, transformed into searchable vectors
We connect to your data sources — PDFs, Word docs, databases, SharePoint, Confluence, S3, APIs — chunk and embed the content using state-of-the-art embedding models, then store it in a high-performance vector database (Pinecone, Qdrant, Weaviate, or pgvector).
- Supports 50+ file formats & live data connectors
- Automatic incremental re-indexing when data changes
- Metadata filtering for access control & precision
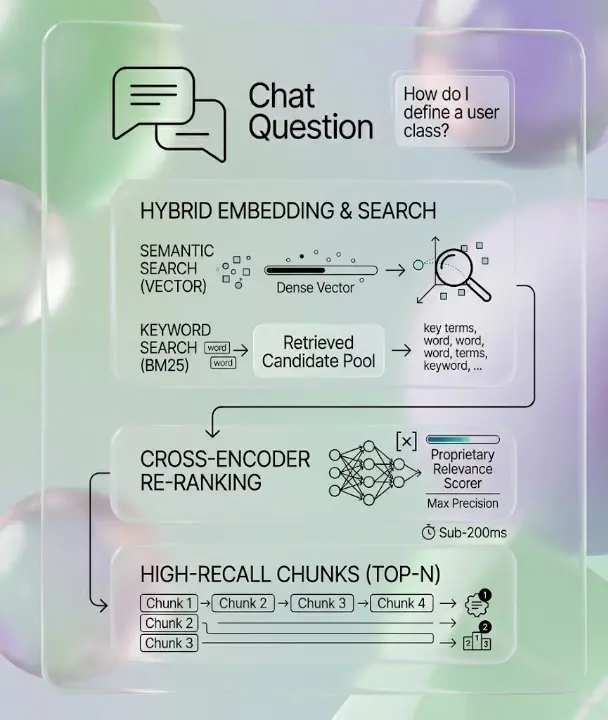
Find the exact context from millions of documents in milliseconds
When a user asks a question, our retrieval layer converts it to an embedding vector and performs lightning-fast semantic similarity search — returning the most relevant content chunks, re-ranked by our proprietary relevance scorer for maximum accuracy.
- Hybrid search (vector + keyword BM25) for higher recall
- Cross-encoder re-ranking for precision
- Sub-200ms retrieval on collections with millions of records

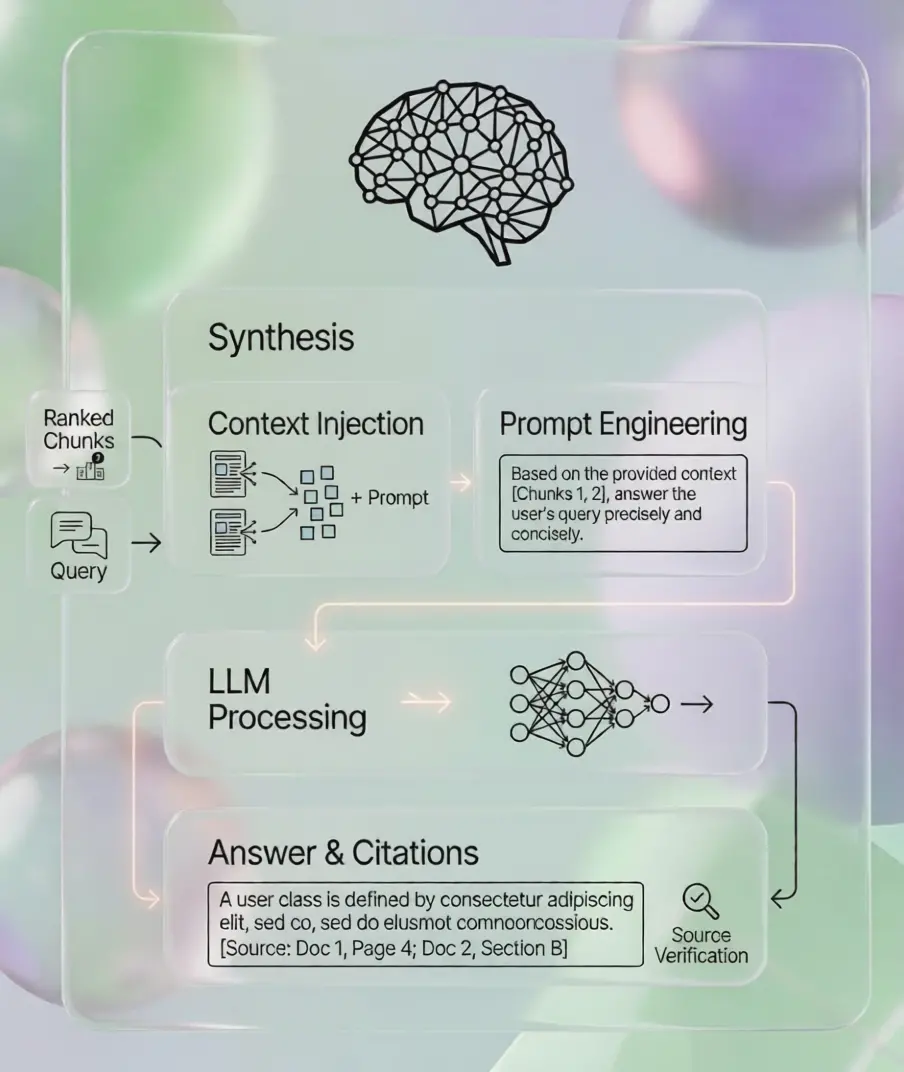
Grounded, source-cited answers your team can trust
The retrieved context is injected into a carefully engineered prompt and sent to your chosen LLM. The model generates a precise, human-readable answer — accompanied by source citations so users can verify every claim against the original document.
- Automatic inline citations with page/section references
- Confidence scoring & fallback messaging
- Full audit log for compliance & traceability
• RAG Pipeline
Data is the King, So we build Data-Intensive Applications
Every RAG system we build is architected from scratch to fit your exact use case, data structure, and security requirements.
Multi-Source Data Ingestion
Connect PDFs, Word files, Excel sheets, SQL databases, REST APIs, SharePoint, Notion, Google Drive, and more. We build custom connectors for any data source your team relies on.
Hybrid Vector + Keyword Search
Combines dense vector semantic search with sparse BM25 keyword matching for best-of-both-worlds retrieval. Higher recall, better precision, fewer missed answers.
Role-Based Access Control
Enforce document-level permissions inside the RAG pipeline. Users only retrieve content they're authorized to see — fully synchronized with your existing IAM, SSO, or LDAP.
Any LLM, Your Choice
We integrate with OpenAI GPT-4o, Anthropic Claude, Google Gemini, Mistral, and self-hosted open-source models (Llama 3, Phi-3, Qwen). No vendor lock-in.
Conversational Memory
Multi-turn conversation support with session memory and context window management. Users can ask follow-up questions naturally — the system remembers the thread.
Analytics & Feedback Loop
Built-in dashboard tracks query volume, retrieval accuracy, user satisfaction scores, and unanswered questions — enabling continuous improvement of your knowledge base.
• Industry
Transforming how industries access knowledge
RAG systems are not one-size-fits-all. Here is how we tailor them for different sectors.
Smart Reports with Charts
Generate reports with interactive charts and visualizations, making data analysis intuitive and actionable. Perfect for financial analysis, market research, and any scenario where insights need to be communicated clearly.
Discuss Your Reports Use Case
AI Support on Your Knowledge Base
Replace generic chatbots with an AI agent that reads your actual product docs, FAQs, and ticketing history. Resolve 70% of tier-1 queries instantly, with accurate, on-brand responses and automatic escalation for complex issues.
Build Your Support RAG
Clinical Docs & Research Q&A
Query clinical guidelines, medical literature, patient records (HIPAA-compliant, on-premise), and research papers. Surface evidence-based answers faster than any manual review process.
Explore Healthcare RAG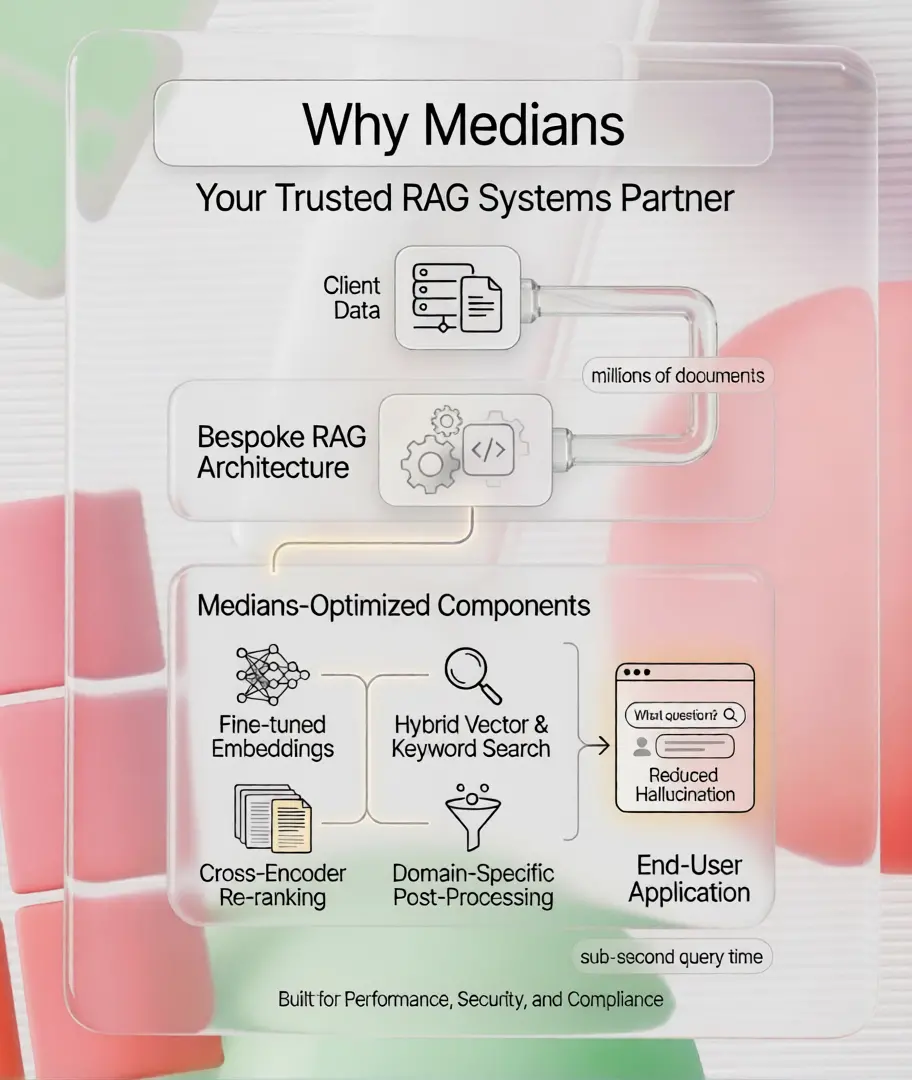
Knowledge Assistant for Teams
Give every employee a brilliant internal search assistant. New hires onboard 3x faster. Senior staff stop fielding repeated questions. HR policies, runbooks, SOPs, and meeting notes all become instantly searchable.
Build Your Team RAGWe don't present ideas. We produce real results.
Built From data-intensive Principles
We don't use code wrappers or pre-built scripts. Every system is custom-engineered for your data schema, data sources, and business requirements.
Security-First by Design
On-premise deployment options, end-to-end encryption, RBAC at the retrieval layer, and full OWASP compliance. Your data never leaves your infrastructure unless you choose cloud.
Reliability & Scalability
Doesn't matter the amount or count of data. Our architecture uses distributed vector stores and async re-indexing queues to handle any scale without degrading response quality.
Consistent + Ongoing Support
We don't disappear after launch. We provide documented APIs, admin dashboards, team training, and a dedicated support channel — so your team can own and evolve the system.
50+
RAG Systems DeployedAcross legal, healthcare, fintech, and enterprise sectors
<200ms
Average Retrieval LatencySub-200ms P95 on collections with 10M+ vectors
98%
Answer Accuracy RateMeasured on client-defined evaluation benchmarks
• Medians
Technologies we work with